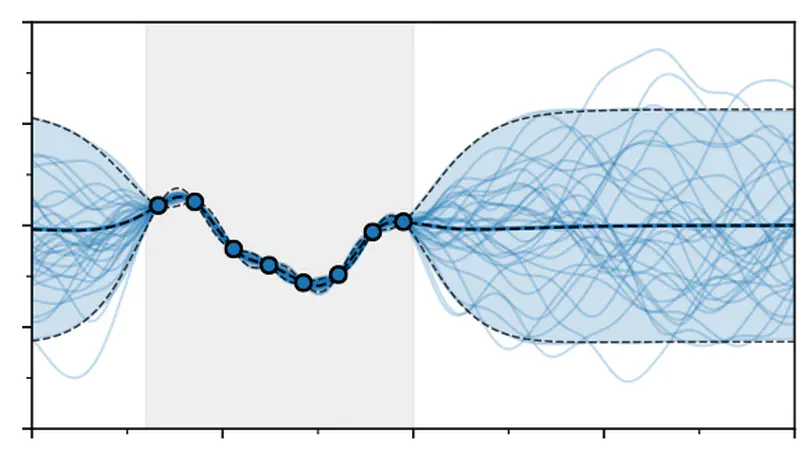
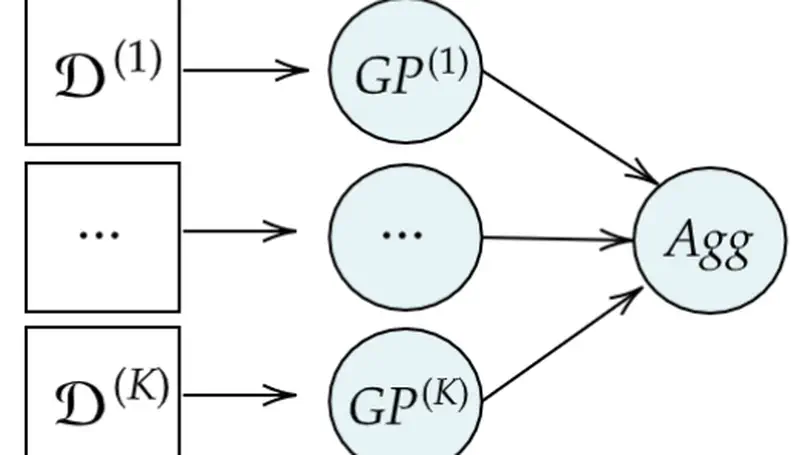
Data is often gathered sequentially in the form of a time series, which consists of sequences of data points observed at successive time points.
Dynamic time warping (DTW) defines a meaningful similarity measure between two time series.
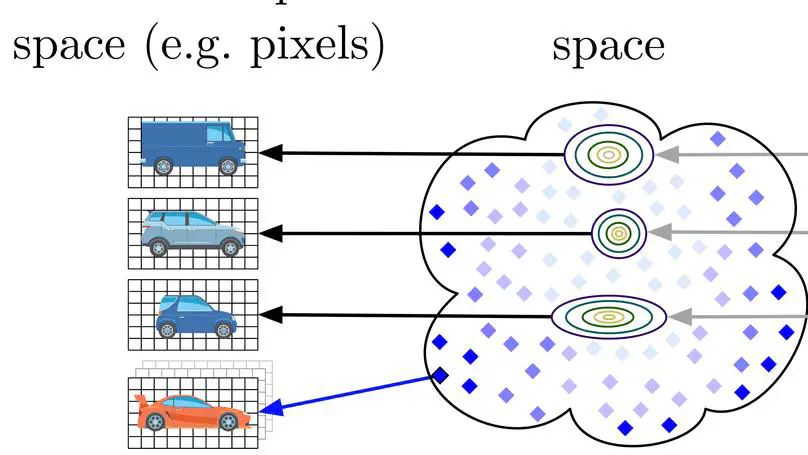
Often times, the pairs of time series we are interested in are defined on different spaces: for instance, one might want to align a video with a corresponding audio wave, potentially sampled at different frequencies.