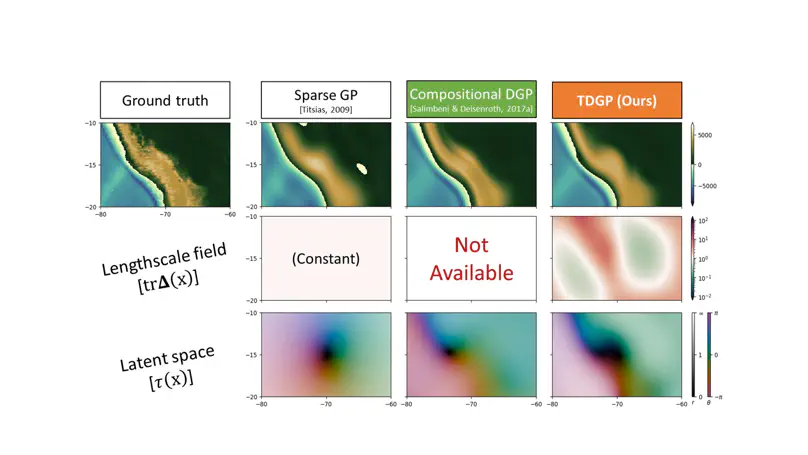
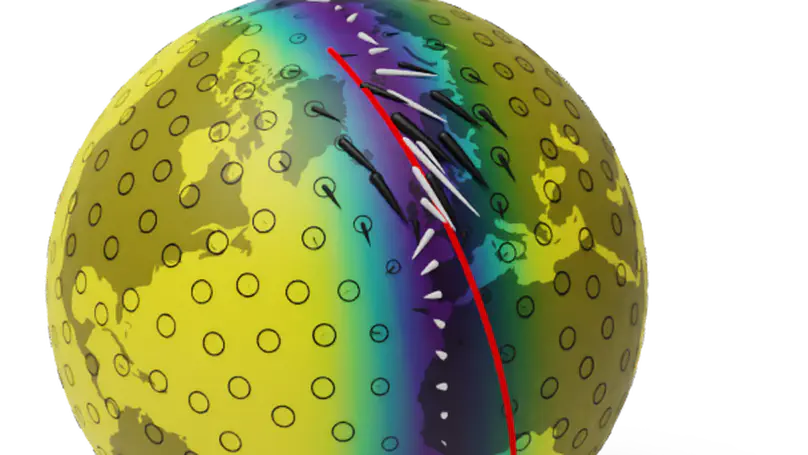
Selecting an appropriate kernel for Gaussian processes (GPs) can be challenging. Deep GPs avoid manual kernel engineering by low-dimensional embeddings of the inputs that explain the output data, but lose all the interpretability of shallow GPs. Alternatively one successively parameterize the lengthscale of a kernel, improving the interpretability but ultimately giving away the notion of learning lower-dimensional embeddings. Both methods are susceptible to particular pathologies which may hinder fitting and limit their interpretability. We propose a novel synthesis of both previous approaches. Each TDGP layer is a local linear transformation generating latent embeddings while also being the lengthscales of a kernel. This model is, unlike previous models, tailored to specifically discover lower-dimensional manifolds in the input data and behaves well when increasing the number of layers.